Matematika A2a 2008/5. gyakorlat
Mozo (vitalap | szerkesztései) (→Példa) |
Mozo (vitalap | szerkesztései) |
||
| 1. sor: | 1. sor: | ||
:''Ez az szócikk a [[Matematika A2a 2008]] alszócikke.'' | :''Ez az szócikk a [[Matematika A2a 2008]] alszócikke.'' | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
==A differenciálás tulajdonságai== | ==A differenciálás tulajdonságai== | ||
| 143. sor: | 105. sor: | ||
:<math> \mathbf{r}^2=0+\mathbf{0}\cdot\mathbf{r}+|\mathbf{r}|\cdot |\mathbf{r}|\,</math> | :<math> \mathbf{r}^2=0+\mathbf{0}\cdot\mathbf{r}+|\mathbf{r}|\cdot |\mathbf{r}|\,</math> | ||
minden '''r'''-re fennáll, így grad('''id'''<sup>2</sup>)('''0''') = '''0''' alkalmas az ε('''r''')=|'''r'''|-rel, tehát '''r'''<sup>2</sup> differenciálható 0-ban is. | minden '''r'''-re fennáll, így grad('''id'''<sup>2</sup>)('''0''') = '''0''' alkalmas az ε('''r''')=|'''r'''|-rel, tehát '''r'''<sup>2</sup> differenciálható 0-ban is. | ||
| + | |||
| + | =='''a''' × ... operátor== | ||
| + | Differenciálható-e és ha igen mi a differenciálja, divergenciája, rotációja a | ||
| + | :<math>\mathbf{v}:\mathbf{R}^3\to\mathbf{R}^3;\quad \mathbf{v}(\mathbf{r})=\mathbf{a}\times\mathbf{r}</math> | ||
| + | leképezésnek, ahol '''a''' előre megadott konstans vektor. | ||
| + | ===Megoldás=== | ||
| + | Az '''a''' × ..., azaz az | ||
| + | :<math>\mathbf{a}\times\mathrm{I}\,</math> | ||
| + | (itt I az identitás leképezés) leképezés lineáris, minthogy a vektoriális szorzás mindkét változójában lineáris ('''v''' ∈ ''Lin''('''R'''<sup>3</sup>;'''R'''<sup>3</sup>)), így differenciálható és differenciálja saját maga: | ||
| + | :<math>\mathrm{d}(\mathbf{a}\times\mathrm{I})(\mathbf{r})=\mathbf{a}\times\mathrm{I}</math> | ||
| + | azaz | ||
| + | :<math>(\mathrm{d}(\mathbf{a}\times\mathrm{I})(\mathbf{r}))\mathbf{h}=\mathbf{a}\times\mathbf{h}</math> | ||
| + | minden '''h''' és '''r''' ∈ '''R'''<sup>3</sup> vektorra. | ||
| + | |||
| + | Jacobi-mátrixa (a sztenderd bázisbeli mátrixa) tetszőleges (x,y,z) pontban: | ||
| + | : <math>\mathrm{J}^{\mathbf{a}\times\mathrm{I}}(x,y,z)= | ||
| + | \begin{bmatrix} | ||
| + | \;\,0 & -a_3& \;\;\,a_2\\ | ||
| + | \;\;\,a_3 & \;\,0 & -a_1\\ | ||
| + | -a_2 & \;\;\,a_1& \;\,0\\ | ||
| + | \end{bmatrix}</math> | ||
| + | Mivel a főátlóbeli elemek mind nullák, ezért ebből rögtön következik, hogy div('''a''' × I)('''r''') = 0. | ||
| + | :<math>[\mathrm{rot}\,\mathbf{v}]_i=\varepsilon_{ijk}\partial_j\varepsilon_{klm}a_lx_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\partial_j x_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\delta_{jm}=\varepsilon_{ijk}\varepsilon_{klj}a_l=</math> | ||
| + | :<math>=\delta_{kk}\delta_{il}a_l-\delta_{ki}\delta_{lk}a_l=3a_i-a_i=2a_i\,</math> | ||
| + | azaz rot '''v''' ('''r''') = 2'''a'''. Az előbb felhasználtuk a kettős vektoriális szorzatra vonatkozó kifejtési tétel indexes alakját, a | ||
| + | :<math>\varepsilon_{ijk}\varepsilon_{klm}=\delta_{jm}\delta_{li}-\delta_{jl}\delta_{im}\,</math> | ||
| + | ami azt mondja, hogy ha az ijk és klm-ben a nem azonos párok jó sorrendben következnek, akkor az epszolon 1-et, ha rossz sorrendben, akkor -1-et ad. | ||
| + | |||
<center> | <center> | ||
A lap 2009. március 5., 16:03-kori változata
- Ez az szócikk a Matematika A2a 2008 alszócikke.
Tartalomjegyzék |
A differenciálás tulajdonságai
Lineáris és affin függvény deriváltja
Az A : Rn  Rm lineáris leképezés differenciálható és differenciálja minden pontban saját maga.
Rm lineáris leképezés differenciálható és differenciálja minden pontban saját maga.
Ugyanis, legyen u ∈ Rn. Ekkor
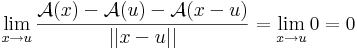
c konstans függény esetén az dc(u)  0 alkalmas differenciálnak, mert
0 alkalmas differenciálnak, mert
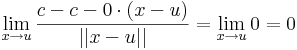
így világos, hogy c + A alakú affin függvények is differenciálhatóak, és differenciáljuk minden pontban az az A lineáris leképezés, melynek eltolásából az affin származik. Ezt szintén behelyettesítéssel ellenőrizhetjük.
Tehát minden u ∈ Rn-re

Példa
Az A: x  2x1 + 3x2 - 4x3 lineáris leképezés differenciálja az u pontban az u-tól független
2x1 + 3x2 - 4x3 lineáris leképezés differenciálja az u pontban az u-tól független
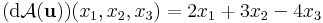
és Jacobi-mátrixa a konstans
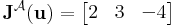
mátrix.
Világos, hogy a
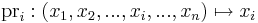
koordináta vagy projekciófüggvény lineáris, differenciálja minden u pontban saját maga és ennek mátrixa:
![[\mathrm{grad}\,\mathrm{pr_i}]=\mathbf{J}^{\mathrm{pr}_i}(\mathbf{u})=\begin{bmatrix}0 & 0 & ... & 1 & ...& 0\end{bmatrix}](/upload/math/f/a/5/fa51c1bb60d1e414a5acb5c8e93ae7d2.png)
ahol az 1 az i-edik helyen áll. Másként
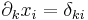
ahol
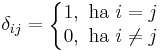
azaz a Kronecker-féle δ szimbólum.
Függvények lineáris kombinációja
Ha f és g a H ⊆ Rn halmazon értelmezett Rm-be képező, az u ∈ H-ban differenciálható függvények, akkor minden λ számra
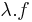 is differenciálható u-ban és
is differenciálható u-ban és 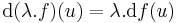 és
és
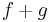 is differenciálható u-ban és
is differenciálható u-ban és 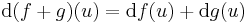
Ugyanis, a mondott differenciálokkal és a
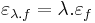
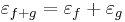
választással, ezek az u-ban folytonosak lesznek és a lineáris résszekel együtt ezek előállítják a skalárszoros és összegfüggvények megváltozásait.
Függvénykompozíció differenciálja
Tétel. Legyen g: Rn ⊃ Rm, az u-ban differenciálható, f: Rm ⊃ Rk a g(u)-ban differenciálható függvény, u ∈ int Dom(f 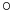 g). Ekkor az
g). Ekkor az
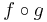 differenciálható u-ban és
differenciálható u-ban és
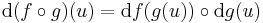
Bizonyítás. Alkalmas ε, A és η B párral, minden x ∈ Dom(f g)-re:
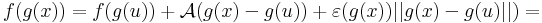
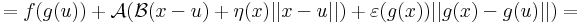
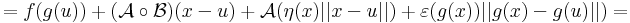
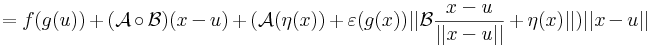
Innen leolvasható a differenciál és a másodrendben eltűnő mennyiség vektortényezője, az
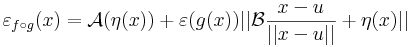
melyben az első tag a 0-hoz tart, mivel a lineáris leképezés a 0-ban folytonos, és η a 0-hoz tart az u-ban. A második tag nulla szor korlátos alakú, hiszen a lineáris leképezés Lipschitz-tuladonsága folytán B minden egységvektoron korlátos értéket vesz fel.
Ennek a tételnek a legegyszerűbb, de már vektorokat tartalmazó formáját írja át "fogyasztható" formába az alábbi
Következmény. Ha g: Rn ⊃ R, az u-ban differenciálható, f: R ⊃ R a g(u)-ban differenciálható függvény, u ∈ int Dom(f g), akkor
- differenciálható u-ban és
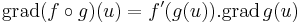
Ahol . a skalárral való szorzást jelöli.
1. Példa
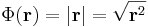
Először a gradienst számítjuk ki. Mivel a gyökfüggvény nem differenciálható a 0-ban, ezért a differenciál csak nemnulla r-re számítható ki. 0-ban a függvény tényleg nem differenciálható, mert a parciális deriváltak nem léteznek.
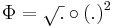
és
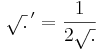 illetve
illetve 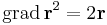
Ezért
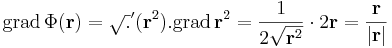
Ha valakinek a differenciál leképezés kell, akkor pedig:
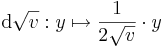
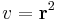
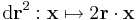
Ezek kompozíciója:
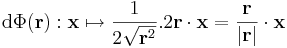
Szemléleti okokból lényeges, hogy itt . a skalárral való szorzás,  a skaláris szorzás.
a skaláris szorzás.
2. Példa
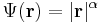
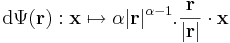
illetve a gradiens:
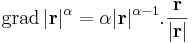
Folytonosság mint szükséges feltétel
Ha f differenciálható u-ban, akkor ott folytonos is, ugyanis minden x-re:
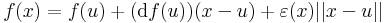
amely tagjai mind folytonosak u-ban.
Skalárfüggvények szorzata
λ, μ: H R, ahol H ⊆ Rn és az u ∈ H-ban mindketten differenciálhatók, akkor λμ is és
![[\mathrm{d}(\lambda\mu)(u)]_{1j}=\partial_j(\lambda\mu)=\mu\partial_j\lambda+\lambda\partial_j\mu=[\mu(u).\mathrm{grad}\,\lambda(u)+\lambda(u).\mathrm{grad}\,\mu(u)]_{j}](/upload/math/c/0/6/c06d0e7630e5abf100915f67de31ed5d.png)
azaz
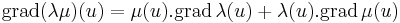
Példa
Számoljuk ki r2 deriváltját a szorzat szabálya szerint.
Egyrészt, ha r ≠ 0, akkor
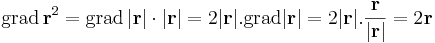
Másrészt, ha r = 0, akkor
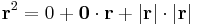
minden r-re fennáll, így grad(id2)(0) = 0 alkalmas az ε(r)=|r|-rel, tehát r2 differenciálható 0-ban is.
a × ... operátor
Differenciálható-e és ha igen mi a differenciálja, divergenciája, rotációja a
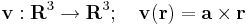
leképezésnek, ahol a előre megadott konstans vektor.
Megoldás
Az a × ..., azaz az
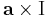
(itt I az identitás leképezés) leképezés lineáris, minthogy a vektoriális szorzás mindkét változójában lineáris (v ∈ Lin(R3;R3)), így differenciálható és differenciálja saját maga:
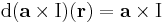
azaz
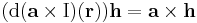
minden h és r ∈ R3 vektorra.
Jacobi-mátrixa (a sztenderd bázisbeli mátrixa) tetszőleges (x,y,z) pontban:
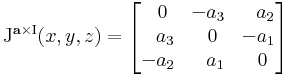
Mivel a főátlóbeli elemek mind nullák, ezért ebből rögtön következik, hogy div(a × I)(r) = 0.
![[\mathrm{rot}\,\mathbf{v}]_i=\varepsilon_{ijk}\partial_j\varepsilon_{klm}a_lx_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\partial_j x_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\delta_{jm}=\varepsilon_{ijk}\varepsilon_{klj}a_l=](/upload/math/6/4/2/642b95a997703a68637ff5897331d591.png)
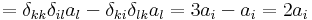
azaz rot v (r) = 2a. Az előbb felhasználtuk a kettős vektoriális szorzatra vonatkozó kifejtési tétel indexes alakját, a
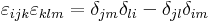
ami azt mondja, hogy ha az ijk és klm-ben a nem azonos párok jó sorrendben következnek, akkor az epszolon 1-et, ha rossz sorrendben, akkor -1-et ad.
| 4. gyakorlat | 6. gyakorlat |