|
|
| (egy szerkesztő 38 közbeeső változata nincs mutatva) |
| 1. sor: |
1. sor: |
| − | :''Ez az szócikk a [[Matematika A2a 2008]] alszócikke.''
| + | ==Differenciálhatóság== |
| − | ==Másodrendű parciális deriváltak== | + | A többváltozós differenciálhatóságot az egyváltozós alábbi átfogalmazásából általánosítjuk: |
| − | Ha ''f'' a ''H'' ⊆ '''R'''<sup>2</sup> halmazon értelmezett '''R'''-be képező, az ''u'' ∈ ''H''-ban differenciálható függvény és a
| + | |
| − | :<math>\mathrm{grad}\,f</math> | + | |
| − | gradiensfüggvény szintén differenciálható ''u''-ban, akkor ''f''-et ''u''-ban kétszer differenciálhatónak nevezzük és az ''f'' függény ''u''-beli másodrendű differenciálja:
| + | |
| − | :<math>\mathrm{d}^2f(u):=\mathrm{d}(\mathrm{grad}\,f)(u)</math>
| + | |
| − | Ennek Jacobi-mátrixa akkor is létezik, ha csak azt feltételezzük, hogy a parciális deriváltak léteznek az ''u'' egykörnyezetében, és ott differenciálhatóak. Ekkor a szóban forgó Jacobi-mátrix
| + | |
| − | :<math>H^f(u)=\begin{bmatrix}
| + | |
| − | \cfrac{\partial^2 f(u)}{\partial x^2} & \cfrac{\partial^2 f(u)}{\partial y\partial x}\\\\
| + | |
| − | \cfrac{\partial^2 f(u)}{\partial x\partial y} & \cfrac{\partial^2 f(u)}{\partial y^2}
| + | |
| − | \end{bmatrix}</math>
| + | |
| − | alakú és Hesse-féle mátrixnak nevezzük.
| + | |
| | | | |
| − | A Young-tétel értelmében ezek másodrendű vegyes parciális deriváltak egyenlők, azaz a Hesse-mátrix szimmetrikus (a d<sup>2</sup>f(u) pedig szimmetrikus tenzor):
| + | :<math>\lim\limits_{x\to u}\frac{f(x)-f(u)-m(x-u)}{|x-u|}=0</math> |
| − | :<math>H^f(u)=(H^f(u))^{\mathrm{T}}=\begin{bmatrix} | + | :<math>\lim\limits_{x\to u+}\frac{f(x)-f(u)-m(x-u)}{x-u}=0\quad\wedge\quad\lim\limits_{x\to u-}\frac{f(x)-f(u)-m(x-u)}{-(x-u)}=0</math> |
| − | \partial_{11} f(u) & \partial_{12} f(u)\\\\ | + | :<math>\lim\limits_{x\to u+}\left(\frac{f(x)-f(u)}{x-u}-m\right)=0,\quad\wedge\quad\lim\limits_{x\to u-}-\left(\frac{f(x)-f(u)}{x-u}-m\right)=0</math> |
| − | \partial_{12} f(u) & \partial_{22} f(u)\\ | + | :<math>\lim\limits_{x\to u+}\frac{f(x)-f(u)}{x-u}=m,\quad\wedge\quad\lim\limits_{x\to u-}-\frac{f(x)-f(u)}{x-u}=-m</math> |
| − | \end{bmatrix}</math>
| + | :<math>\lim\limits_{x\to u}\frac{f(x)-f(u)}{x-u}=m</math> |
| | | | |
| − | '''Megjegyzés.''' Elvileg a
| |
| − | :<math>\{x\in \mathbf{R}^2\mid f\in\mathrm{Diff}(x)\}\rightarrow\mathrm{Lin}(\mathbf{R}^2;\mathbf{R});\quad x\mapsto \mathrm{d}f(x)</math>
| |
| − | leképezésnek kellett volna a differenciálját venni az ''u'' pontban, és ezt tekinteni a differenciálnak. Ám ez nem '''R'''<sup>m</sup>-be, hanem egy általánosabb normált térbe, a '''R'''<sup>2</sup> <math>\to</math> '''R''' lináris leképezések terébe képez (az ún. kétváltozós lineáris funkcionálok terébe). Ebben a norma az operátornorma (az operátor minimális Lipschitz-konstansa), és a tér véges dimenziós. A differenciálhatóság pontosan ugyanúgy értelmezhető, mint a többváltozs esetben. Ekkor az ''f'' függvény ''u''-beli másodrendű differenciálja az
| |
| − | :<math>\mathrm{d}(\mathrm{d}f(.))(u)=\mathcal{A}:\mathbf{R}^2\rightarrow\mathrm{Lin(\mathbf{R}^2;\mathbf{R})} </math>
| |
| − | lineáris leképezés, melyre teljesül a
| |
| − | :<math>\lim\limits_{x\to u}\frac{\mathrm{d}f(x)-\mathrm{d}f(u)-\mathcal{A}(x-u)}{||x-u||}=0_{\mathrm{Lin(\mathbf{R}^2;\mathbf{R})}}</math>
| |
| − | A bázisvektorokon ''A'' a következőt veszi fel:
| |
| − | :<math>\lim\limits_{t\to 0}\frac{\mathrm{d}f(u+te_1)-\mathrm{d}f(u)}{t}=\mathcal{A}(e_1)</math>
| |
| − | ennek a mátrixa a sztenderd bázisban
| |
| − | :<math>\lim\limits_{t\to 0}\frac{[\partial_1 f(u+te_1)\quad\partial_2 f(u+te_1)]-[\partial_1 f(u)\quad\partial_2 f(u)]}{t}=[\mathcal{A}_1(e_1)\quad \mathcal{A}_2(e_1)]</math>
| |
| − | ami a kivonás és az osztást komponensenként elvégezve az parciális deriváltak első változó szerinti parciális deriváltjait adja:
| |
| − | :<math>[\mathcal{A}_1(e_1)\quad \mathcal{A}_2(e_1)]=[\partial_1(\partial_1 f)(u)\quad \partial_1(\partial_2 f)(u)]=[\partial_{11} f(u)\quad \partial_{12}f(u)]</math>
| |
| | | | |
| − | ==A differenciálás tulajdonságai==
| + | '''Definíció.''' Legyen ''f'': '''R'''<sup>n</sup> <math>\supset\!\longrightarrow</math> '''R'''<sup>m</sup> és ''u'' ∈ int Dom(f). Azt mondjuk, hogy ''f'' '''differenciálható''' az ''u'' pontban, ha létezik olyan ''A'': '''R'''<sup>n</sup> <math>\to</math> '''R'''<sup>m</sup> lineáris leképezés, hogy |
| − | ===Lineáris és affin függvény deriváltja===
| + | :<math>\lim\limits_{x\to u}\frac{f(x)-f(u)-\mathcal{A}(x-u)}{||x-u||_{\mathbf{R}^n}}=0_{\mathbf{R}^m}</math> |
| − | Az ''A'' : '''R'''<sup>n</sup> <math>\to</math> '''R'''<sup>m</sup> lineáris leképezés differenciálható és differenciálja minden pontban saját maga.
| + | Ekkor ''A'' egyértelmű és az ''f'' leképezés ''u''-bent beli '''differenciál'''jának nevezzük és d''f''(''u'')-val vagy D''f''(u)-val jelöljük. Ezt a fogalmat néha ''teljes differenciál''nak, ''totális differenciál''nak vagy ''Fréchet-derivált''nak is mondjuk. |
| | | | |
| − | ''Ugyanis, '' legyen ''u'' ∈ '''R'''<sup>n</sup>. Ekkor | + | '''Megjegyzés.''' A fenti határérték 0 volta egyenértékű a következő kijelentéssel. Létezik ''A''': ''R'''<sup>n</sup> <math>\to</math> '''R'''<sup>m</sup> lineáris leképezés és ε: Dom(''f'') <math>\to</math> '''R'''<sup>m</sup> függvény, melyre: |
| | + | : ε folytonos u-ban és ε(u)=0, továbbá |
| | + | minden ''x'' ∈ Dom(''f'')-re: |
| | + | : <math>f(x)=f(u)+\mathcal{A}(x-u)+\varepsilon(x)||x-u||</math> |
| | + | '''Megjegyzés.''' Azt, hogy ''A'' egyértelmű, a következőkkel bizonyíthatjuk. Legyen ''A'' és ''B'' is a mondott tulajdonságú, azaz létezzenek ε és η az ''u''-ban eltűnő és ott folytonos Dom(''f'')-en értelmezett függvények, melyekre teljesül, hogy minden ''x'' ∈ Dom(''f'')-re |
| | + | :<math>f(x)=f(u)+\mathcal{A}(x-u)+\varepsilon(x)||x-u||</math> |
| | + | :<math>f(x)=f(u)+\mathcal{B}(x-u)+\eta(x)||x-u||</math> |
| | + | ezeket kivonva egymásból és használva '''minden''' ''x''-re: |
| | + | :<math>(\mathcal{A}-\mathcal{B})(x-u)+(\varepsilon(x)-\eta(x))||x-u||=0</math> |
| | + | így minden x = u + ty értékre is az azonosan nullát kapjuk, ha t pozitív szám, y pedig rögzített nemnulla vektor, azaz minden t-re |
| | + | :<math>(\mathcal{A}-\mathcal{B})ty+(\varepsilon(u+ty)-\eta(u+ty))||ty||=0</math> |
| | + | az azonosan 0 függény határértéke t<math>\to</math> 0 esetén szintén nulla: |
| | + | :<math> 0=\lim\limits_{t\to 0}\frac{(\mathcal{A}-\mathcal{B})(ty)+(\varepsilon(u+ty)-\eta(u+ty))||ty||}{t}=(\mathcal{A}-\mathcal{B})y</math> |
| | + | hiszen t-t kiemelhetünk és egyszerűsíthetünk és t<math>\to</math> 0 esetén |
| | + | ε és η nullává válik. |
| | + | Ez viszont pont azt jelenti, hogy a két lineéris operátor azonosan egyenlő. |
| | | | |
| − | :<math>\lim\limits_{x\to u}\frac{\mathcal{A}(x)-\mathcal{A}(u)-\mathcal{A}(x-u)}{||x-u||}=\lim\limits_{x\to u}0=0</math>
| + | ==Jacobi-mátrix== |
| | + | A d''f''(''u'') lineáris leképezés (<math>e_1</math>,<math>e_2</math>,...,<math>e_n</math>) szetenderd bázisbeli mátrixa legyen: [d''f''(''u'')] = '''A'''. Vizsgáljuk mibe viszi a bázisokat d''f''(''u'') leképezés! |
| | | | |
| − | c konstans függény esetén az d''c''(''u'') <math>\equiv</math> 0 alkalmas differenciálnak, mert
| + | Írjuk fel a definíciót, de az <math>e_1</math> egységvektor mentén tartsunk ''u''-hoz: ''x'' = ''u'' + ''t''<math>e_1</math>. Ekkor |
| − | :<math>\lim\limits_{x\to u}\frac{c-c-0\cdot(x-u)}{||x-u||}=\lim\limits_{x\to u}0=0</math> | + | :<math>x-u=te_1\,</math> |
| − | így világos, hogy c + ''A'' alakú affin függvények is differenciálhatóak, és differenciáljuk minden pontban az az ''A'' lineáris leképezés, melynek eltolásából az affin származik. Ezt szintén behelyettesítéssel ellenőrizhetjük.
| + | ami azért hasznos, mert a |
| | + | :<math>\mathcal{A}(x-u)=\mathcal{A}(te_1)\,</math> |
| | + | alakból kiemelhetó t: |
| | + | :<math>0=\lim\limits_{t\to 0}\frac{f(u+te_1)-f(u)-\mathcal{A}(te_1)}{t}=</math> |
| | + | :::<math>=\lim\limits_{t\to 0}\frac{f(u+te_1)-f(u)-t.\mathcal{A}(e_1)}{t}=</math> |
| | + | :::<math>=-\mathcal{A}(e_1)+\lim\limits_{t\to 0}\frac{f(u+te_1)-f(u)}{t}</math> |
| | + | azaz |
| | + | :<math>\mathcal{A}(e_1)=\lim\limits_{t\to 0}\frac{f(u+te_1)-f(u)}{t}=\partial_1 f(u)</math> |
| | + | vagyis ''f'' koordinátafüggvényeinek az első változó szerinti parciális deriváltja az ''u'' pontban. A többi oszlopvektor ugyanígy: |
| | | | |
| − | Tehát minden ''u'' ∈ '''R'''<sup>n</sup>-re
| + | :<math>[\mathrm{d}f(u)]=\mathbf{J}^f(u)=\begin{bmatrix} |
| − | :<math>\mathrm{d}\mathcal{A}(u)=\mathcal{A},\quad\quad\mathrm{d}c(u)\equiv 0,\quad\quad\mathrm{d}(b+\mathcal{A}\circ(id-a))(u)=\mathcal{A}</math> | + | \partial_1 f_1(u) & \partial_2 f_1(u) & \dots & \partial_n f_1(u)\\ |
| | + | \partial_1 f_2(u) & \partial_2 f_2(u) & \dots & \partial_n f_2(u)\\ |
| | + | \vdots & \vdots & \ddots & \vdots \\ |
| | + | \partial_1 f_m(u) & \partial_2 f_m(u) & \dots & \partial_n f_m(u)\\ |
| | + | \end{bmatrix}</math> |
| | + | amelyet '''Jacobi-mátrix'''nak nevezünk. |
| | | | |
| − | '''Példa.''' | + | '''Következmény.''' Tehát. ha f totálisan differenciálható, akkor parciálisan is differenciálható és a differenciál sztenderd bázisbeli mátrixa a Jacobi-mátrix. |
| | | | |
| − | Az ''A'': '''x''' <math>\mapsto</math> 2<math>x_1</math> + 3<math>x_2</math> - 4<math>x_3</math> lineáris leképezés differenciálja az '''u''' pontban az '''u'''-tól független
| + | Azaz: |
| − | :<math>(\mathrm{d}\mathcal{A}(\mathbf{u}))(x_1,x_2,x_3)=2x_1+3x_2-4x_3\,</math>
| + | :'''teljes''' differenciálhatóság <math>\Longrightarrow</math> '''parciális''' differenciálhatóság |
| − | és Jacobi-mátrixa a konstans
| + | de ez fordítva már nem igaz: |
| − | :<math>\mathbf{J}^\mathcal{A}(\mathbf{u})=\begin{bmatrix}2 & 3 & -4\end{bmatrix}</math>
| + | : '''parciális''' differenciálhatóság <math>\not\Rightarrow</math> '''teljes''' differenciálhatóság |
| − | mátrix.
| + | Erre vonatkozik a két alábbi példa. |
| | | | |
| − | Világos, hogy a
| |
| − | :<math>\mathrm{pr}_i:(x_1,x_2,...,x_i,...,x_n)\mapsto x_i</math>
| |
| − | koordináta vagy projekciófüggvény lineáris, differenciálja minden '''u''' pontban saját maga és ennek mátrixa:
| |
| − | :<math>[\mathrm{grad}\,\mathrm{pr_i}]=\mathbf{J}^{\mathrm{pr}_i}(\mathbf{u})=\begin{bmatrix}0 & 0 & ... & 1 & ...& 0\end{bmatrix}</math>
| |
| − | ahol az 1 az i-edik helyen áll. Másként
| |
| − | :<math>\partial_kx_i=\delta_{ki}</math>
| |
| − | ahol
| |
| − | :<math>\delta_{ij}=\left\{\begin{matrix}1, \mbox{ ha }i=j\\0, \mbox{ ha }i\ne j \end{matrix}\right.</math>
| |
| − | azaz a Kronecker-féle δ szimbólum.
| |
| | | | |
| − | ===Függvények lineáris kombinációja===
| |
| − | Ha ''f'' és ''g'' a ''H'' ⊆ '''R'''<sup>n</sup> halmazon értelmezett '''R'''<sup>m</sup>-be képező, az ''u'' ∈ ''H''-ban differenciálható függvények, akkor minden λ számra
| |
| − | :<math>\lambda.f\,</math> is differenciálható ''u''-ban és <math>\mathrm{d}(\lambda.f)(u)=\lambda.\mathrm{d}f(u)\,</math> és
| |
| − | :<math>f+g\,</math> is differenciálható ''u''-ban és <math>\mathrm{d}(f+g)(u)=\mathrm{d}f(u)+\mathrm{d}g(u)\,</math>
| |
| − | ''Ugyanis,'' a mondott differenciálokkal és a
| |
| − | :<math>\varepsilon_{\lambda.f}=\lambda.\varepsilon_{f}\,</math>
| |
| − | :<math>\varepsilon_{f+g}=\varepsilon_{f}+\varepsilon_{g}\,</math>
| |
| − | választással, ezek az ''u''-ban folytonosak lesznek és a lineáris résszekel együtt ezek előállítják a skalárszoros és összegfüggvények megváltozásait.
| |
| − | ===Függvénykompozíció differenciálja===
| |
| − | '''Tétel. ''' Legyen ''g'': '''R'''<sup>n</sup> ⊃<math>\to</math> '''R'''<sup>m</sup>, az ''u''-ban differenciálható, ''f'': '''R'''<sup>m</sup> ⊃<math>\to</math> '''R'''<sup>k</sup> a ''g''(''u'')-ban differenciálható függvény, ''u'' ∈ int Dom(''f'' <math>\circ</math> ''g''). Ekkor az
| |
| − | :<math>f\circ g</math> differenciálható ''u''-ban és
| |
| − | :<math> \mathrm{d}(f\circ g)(u)=\mathrm{d}f(g(u))\circ\mathrm{d}g(u)</math>
| |
| − |
| |
| − | ''Bizonyítás. '' Alkalmas ε, ''A'' és η ''B'' párral, minden ''x'' ∈ Dom(''f'' <math>\circ</math> ''g'')-re:
| |
| − | :<math>f(g(x))=f(g(u))+\mathcal{A}(g(x)-g(u))+\varepsilon(g(x))||g(x)-g(u)||)=</math>
| |
| − | ::<math>=f(g(u))+\mathcal{A}(\mathcal{B}(x-u)+\eta(x)||x-u||)+\varepsilon(g(x))||g(x)-g(u)||)=</math>
| |
| − | ::<math>=f(g(u))+(\mathcal{A}\circ\mathcal{B})(x-u)+\mathcal{A}(\eta(x)||x-u||)+\varepsilon(g(x))||g(x)-g(u)||)=</math>
| |
| − | ::<math>=f(g(u))+(\mathcal{A}\circ\mathcal{B})(x-u)+(\mathcal{A}(\eta(x))+\varepsilon(g(x))||\mathcal{B}\frac{x-u}{||x-u||}+\eta(x)||)||x-u||</math>
| |
| − | Innen leolvasható a differenciál és a másodrendben eltűnő mennyiség vektortényezője, az
| |
| − | :<math>\varepsilon_{f\circ g}(x)=\mathcal{A}(\eta(x))+\varepsilon(g(x))||\mathcal{B}\frac{x-u}{||x-u||}+\eta(x)||</math>
| |
| − | melyben az első tag a 0-hoz tart, mivel a lineáris leképezés a 0-ban folytonos, és η a 0-hoz tart az ''u''-ban. A második tag nulla szor korlátos alakú, hiszen a lineáris leképezés Lipschitz-tuladonsága folytán ''B'' minden egységvektoron korlátos értéket vesz fel.
| |
| − |
| |
| − | '''Példa.'''
| |
| − | :<math>\Phi(\mathbf{r})=|\mathbf{r}|=\sqrt{\mathbf{r}^2}</math>
| |
| − | Mivel a gyökfüggvény nem differenciálható a 0-ban, ezért a differenciál csak nemnulla '''r'''-re számítható ki:
| |
| − | :<math>\mathrm{d}\Phi(\mathbf{r}):\mathbf{x}\mapsto \frac{1}{2\sqrt{\mathbf{r}^2}}.2\mathbf{r}\cdot\mathbf{x}=\frac{\mathbf{r}}{|\mathbf{r}|}\cdot\mathbf{x}</math>
| |
| − | illetve a gradiens:
| |
| − | :<math>\mathrm{grad}\,|\mathbf{r}|=\frac{\mathbf{r}}{|\mathbf{r}|}</math>
| |
| − | Szemléleti okokból lényeges, hogy itt . a skalárral való szorzás, <math>\cdot</math> a skaláris szorzás.
| |
| − |
| |
| − | :<math>\Psi(\mathbf{r})=|\mathbf{r}|^{\alpha}</math>
| |
| − | :<math>\mathrm{d}\Psi(\mathbf{r}):\mathbf{x}\mapsto \alpha|\mathbf{r}|^{\alpha-1}.\frac{\mathbf{r}}{|\mathbf{r}|}\cdot\mathbf{x}</math>
| |
| − | illetve a gradiens:
| |
| − | :<math>\mathrm{grad}\,|\mathbf{r}|^\alpha=\alpha|\mathbf{r}|^{\alpha-1}.\frac{\mathbf{r}}{|\mathbf{r}|}</math>
| |
| − | ===Folytonosság mint szükséges feltétel===
| |
| − | Ha ''f'' differenciálható ''u''-ban, akkor ott folytonos is, ugyanis minden ''x''-re:
| |
| − | :<math>f(x)=f(u)+(\mathrm{d}f(u))(x-u)+\varepsilon(x)||x-u||</math>
| |
| − | amely tagjai mind folytonosak ''u''-ban.
| |
| − |
| |
| − | ==Teljes és parciális differenciálhatóság==
| |
| − | Ha az ''f'':'''R'''<sup>n</sup> ⊃<math>\to</math> '''R'''<sup>m</sup> függvény differenciálható az ''u'' pontban, akkor ott minden parciális deriváltja létezik és teljesül:
| |
| − | :<math>[(df(u))e_j]_i=\partial_j f_i(u)\,</math>
| |
| − | ahol <math>e_j</math> a j-edik szetenderd bázisvektor, <math> [.]_i</math> pedig az i-edik komponenst jelenti sztenderd bázisban.
| |
| − |
| |
| − | Ez az ellenkező irányban nem következik. Ez majdnem nyilvánvaló, de csak tekintsük az
| |
| − | :<math>f(x,y)=\left\{\begin{matrix}\frac{xy}{x^2+y^2}& \mbox{, ha }&(x,y)\ne (0,0)\\
| |
| − | 0&\mbox{, ha }&(x,y)=(0,0)\end{matrix}\right.</math>
| |
| − | :<gnuplot>
| |
| − | set pm3d
| |
| − | set size 0.8,0.8
| |
| − | set xrange [-1:1]
| |
| − | set yrange [-1:1]
| |
| − | set zrange [-2:2]
| |
| − | set view 50,30,1,1
| |
| − | unset xtics
| |
| − | unset ytics
| |
| − | unset ztics
| |
| − | unset key
| |
| − | unset colorbox
| |
| − | splot x*y/(x*x+y*y)
| |
| − | </gnuplot>
| |
| − | (0,0)-ban a parciális függvények az azonosan 0 függvény, mely persze deriválható a 0-ban, de a függvény még csak nem is folytonos (0,0)-ban, mely szükséges feltétele a teljes differenciálhatóságnak.
| |
| − |
| |
| − | Egy másik, folytonos példa az
| |
| − | :<math>f(x,y)=\left\{\begin{matrix}\frac{xy}{\sqrt{x^2+y^2}}& \mbox{, ha }&(x,y)\ne (0,0)\\
| |
| − | 0&\mbox{, ha }&(x,y)=(0,0)\end{matrix}\right.</math>
| |
| − | :<gnuplot>
| |
| − | set pm3d
| |
| − | set size 0.8,0.8
| |
| − | set xrange [-1:1]
| |
| − | set yrange [-1:1]
| |
| − | set zrange [-2:2]
| |
| − | set view 50,30,1,1
| |
| − | unset xtics
| |
| − | unset ytics
| |
| − | unset ztics
| |
| − | unset key
| |
| − | unset colorbox
| |
| − | splot x*y/(sqrt(x*x+y*y))
| |
| − | </gnuplot>
| |
| − | Ekkor az iránymenti deriváltakat kell vizsgálnunk. Ha van differenciál a (0,0)-ban, akkor az csak az azonosan nulla leképezés lehet a parciális deriváltak miatt. Ám, polárkoordinátákra áttérve:
| |
| − | :<math>f(x(r,\varphi),y(r,\varphi))=\frac{r^2\cos\varphi\sin\varphi}{r}=r\cos\varphi\sin\varphi=r\cdot \frac{1}{2}\sin 2\varphi</math>
| |
| − | φ = π/4-et és π + π/4-et véve a vetületfüggvény a
| |
| − | :<math>t\mapsto\frac{1}{2}|t|</math>,
| |
| − | ami nem differenciálható a 0-ban.
| |
| − |
| |
| − | Megfordításról a következő esetben beszélhetünk.
| |
| − |
| |
| − | '''Tétel.''' Ha az ''f'':'''R'''<sup>n</sup> ⊃<math>\to</math> '''R'''<sup>m</sup> függvény minden parciális deriváltfüggvénye létezik az ''u'' egy környezetében és ''u''-ban a parciális deriváltak folytonsak, akkor ''u''-ban ''f'' differenciálható. (Sőt, folytonosan differenciálható.)
| |
| − |
| |
| − | ''Bizonyítás.'' Elegendő az m = 1 esetet vizsgálni. Továbbá a bizonyítás elve nem változik, ha csak az n = 2 esetet tekintjük. Legyen x az u mondott környezetéből vett pont, és x = (<math>x_1</math>,<math>x_2</math>), v=(<math>u_1</math>,<math>x_2</math>), u=(<math>u_1</math>,<math>u_2</math>) Ekkor az [x,v] szakaszon ∂<sub>1</sub>f-hez a Lagrange-féle középértéktétel miatt létezik olyan ξ(<math>x_1</math>)∈[<math>x_1</math>,<math>u_1</math>] szám, és a [v,u] szakaszon ∂<sub>2</sub>f-hez ζ(<math>x_2</math>)∈[<math>x_2</math>,<math>u_2</math>] szám, hogy
| |
| − | :<math>f(x)-f(u)=f(x)-f(v)+f(v)-f(u)=\,</math>
| |
| − | :<math>=\partial_1 f(\xi(x_1),x_2)(x_1-u_1)+\partial_2 f(u_1,\zeta(x_2))(x_2-u_2)=</math>
| |
| − | :<math>=\partial_1f(u)(x_1-u_1)+\partial_2f(u)(x_2-u_2)+</math>
| |
| − | :<math>+(\partial_1 f(\xi(x_1),x_2)-\partial_1f(u))(x_1-u_1)+(\partial_2 f(u_1,\zeta(x_2))-\partial_2f(u))(x_2-u_2)</math>
| |
| − | itt az
| |
| − | :<math>\varepsilon_1(x)=\partial_1 f(\xi(x_1),x_2)-\partial_1f(u)</math> és <math>\varepsilon_2(x)=\partial_2 f(x_1,\zeta(x_2))-\partial_2f(u)</math>
| |
| − | függvények folytonosak ''u''-ban (még ha a ξ, ζ függvények nem is azok), és értékük az ''u''-ban 0. Világos, hogy ez azt jelenti, hogy f differenciálható ''u''-ban.
| |
| − | ===Skalárfüggvények szorzata===
| |
| − | λ, μ: ''H'' <math>\to</math> '''R''', ahol ''H'' ⊆ '''R'''<sup>n</sup> és az ''u'' ∈ ''H''-ban mindketten differenciálhatók, akkor λμ is és
| |
| − | :<math>[\mathrm{d}(\lambda\mu)(u)]_{1j}=\partial_j(\lambda\mu)=\mu\partial_j\lambda+\lambda\partial_j\mu=[\mu(u).\mathrm{grad}\,\lambda(u)+\lambda(u).\mathrm{grad}\,\mu(u)]_{j}</math>
| |
| − | azaz
| |
| − | :<math>\mathrm{grad}(\lambda\mu)(u)=\mu(u).\mathrm{grad}\,\lambda(u)+\lambda(u).\mathrm{grad}\,\mu(u)</math>
| |
| − | ==Indexes deriválás==
| |
| − | Most csak a sokféle szorzat deriváltjának értékét számítjuk ki. Minden esetben igazolható, hogy ha a formulákban szereplő összes derivált létezik, akkor a formula érvényes (sőt, ha a függvények az adott pontban differenciálhatók, akkor a szorzat is differenciálható az adott pontban). Az mátrixelemeket indexesen számítjuk.
| |
| − | ===Deriválttenzor és invariánsai===
| |
| − | Ha '''A''' az ''f'':'''R'''<sup>n</sup> ⊃<math>\to</math> '''R'''<sup>n</sup> leképezés differenciálja az ''u'' pontban, akkor '''A'''-t deriválttenzornak nevezzük. Minden tenzor egyértelműen előáll egy szimmetrikus és egy antiszimmetrikus tenzor összegeként:
| |
| − | :<math>\mathbf{A}=\mathbf{A}_{s}+\mathbf{A}_a\,</math>
| |
| − | Ebből a szimmetrikus rész főátlbeli elemeinek összege minden bázisban ugyanaz a skaláris érték, melyet a tenzor nyomának, illetve a függvény divergenciájának nevezzük:
| |
| − | :<math>\mathrm{div}(f)(u)=\mathrm{trace}(\mathbf{A})</math> illetve <math>\mathrm{div}(f)=\sum\limits_{i=1}^n\partial_i f_i=*\partial_i f_i*</math>
| |
| − | Az utóbbi írásmód a koordinátás alakban az úgy nevezett Einstein-féle jelölési konvenció, amelynek elve, hogy a kétszer stereplő indexekre automatikusan szumma értendő.
| |
| − | ''f'':'''R'''<sup>3</sup> ⊃<math>\to</math> '''R'''<sup>3</sup>
| |
| − | esetben a tenzor antiszimmetrikus részéhez egyértelműen létezik egy olyan '''a''' vektor, hogy minden '''r'''-re:
| |
| − | :<math>\mathbf{A}_a\mathbf{r}=\mathbf{a}\times\mathbf{r}</math>
| |
| − | mely vektort az ''f'' rotációjának nevezzük:
| |
| − | :<math>\mathrm{rot}f(u)\,</math> és <math>[\mathrm{rot}f(u)]_i=\sum\limits_{j,k=1}^3\varepsilon_{ijk}\partial_j f_k=*\varepsilon_{ijk}\partial_j f_k*</math>
| |
| − | ahol
| |
| − | :<math>\varepsilon_{ijk}=\left\{\begin{matrix}
| |
| − | 1, & \mbox{ha} & (ijk)\in\{(123),(231),(312)\} \\
| |
| − | -1, & \mbox{ha} & (ijk)\in\{(321),(213),(132)\} \\
| |
| − | 0, & \mbox{egyebkent}
| |
| − | \end{matrix}\right.</math>
| |
| − | a Levi-Civita-szimbólum.
| |
| − |
| |
| − | ====Skalárfüggvénnyel való szorzás====
| |
| − | λ: ''H'' <math>\to</math> '''R''', ''f'':''H'' <math>\to</math> '''R'''<sup>m</sup>, ahol ''H'' ⊆ '''R'''<sup>n</sup> és az ''u'' ∈ ''H''-ban mindketten differenciálhatók, akkor λ.''f'' is és
| |
| − | :<math>[\mathrm{d}(\lambda.f)(u)]_{ij}=\partial_j(\lambda.f)=\partial_j\lambda f_i=f_i\partial_j\lambda+\lambda \partial_jf_i </math>
| |
| − | azaz
| |
| − | :<math>\mathrm{d}(\lambda.f)(u)=f(u)\scriptstyle{\otimes}</math><math>\mathrm{grad}\lambda(u)+\lambda(u).\mathrm{d}f(u)\,</math>
| |
| − | ahol <math>\scriptstyle{\otimes}</math> a diadikus szorzat, melynek koordinátamátrixa egy oszlopvektor (balról) és egy sorvektor (jobbról) mátrixszorzatából adódik. Ez ritkán kell teljes egészében, a két invariáns (rot-nál csak 3×3-as esetben) a gyakoribb.
| |
| − | :<math>\mathrm{div}(\lambda.f)(u)=f(u)\cdot \mathrm{grad}\lambda(u)+\lambda(u)\cdot \mathrm{div}f(u)</math>
| |
| − | :<math>[\mathrm{rot}(\lambda.f)(u)]_i=\varepsilon_{ijk}\partial_j\lambda f_k=\varepsilon_{ijk}(\partial_j\lambda)f_k+\lambda\varepsilon_{ijk}\partial_jf_k=</math>
| |
| − | :<math>=[\mathrm{grad}\lambda(u)\times f(u)+\lambda(u).\mathrm{rot}f(u)]_i</math>
| |
| − |
| |
| − | ====Vektorfüggvények skaláris szorzata====
| |
| − | ''f'',''g'':''H'' <math>\to</math> '''R'''<sup>m</sup>, ahol ''H'' ⊆ '''R'''<sup>n</sup> és az ''u'' ∈ ''H''-ban mindketten differenciálhatók, akkor ''f''<math>\cdot</math>''g'' is és
| |
| − | :<math>[\mathrm{d}(f\cdot g)(u)]_{1j}=\partial_j(f\cdot g)=\partial_j f_kg_k=f_k\partial_j g_k+g_k \partial_j f_k </math>
| |
| − | azaz
| |
| − | :<math>\mathrm{d}(f\cdot g)(u)=(f(u)\cdot)\circ \mathrm{d}g(u)+(g(u)\cdot)\circ \mathrm{d}f(u)</math>
| |
| − | illetve a Jacobi-mátrixszal:
| |
| − | :<math>\mathbf{J}^{f\cdot g}(u)=[f(u)]^\mathrm{T}\cdot \mathbf{J}^g(u) +
| |
| − | [g(u)]^\mathrm{T}\cdot \mathbf{J}^f(u)</math>
| |
| − | ahol <math>[.]^\mathrm{T}</math> az oszlopvektor transzponáltját, <math>(v\cdot)</math> pedig a v vektorral történő skaláris szorzás operátorát jelöli.
| |
| − |
| |
| − |
| |
| | | | |
| | | | |
| 217. sor: |
70. sor: |
| | |} | | |} |
| | </center> | | </center> |
| | + | |
| | + | [[Kategória:Matematika A2]] |
A többváltozós differenciálhatóságot az egyváltozós alábbi átfogalmazásából általánosítjuk:
így minden x = u + ty értékre is az azonosan nullát kapjuk, ha t pozitív szám, y pedig rögzített nemnulla vektor, azaz minden t-re
Erre vonatkozik a két alábbi példa.
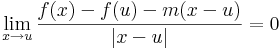

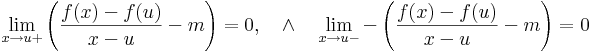
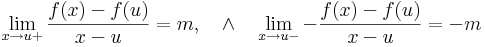
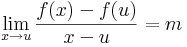
 Rm és u ∈ int Dom(f). Azt mondjuk, hogy f differenciálható az u pontban, ha létezik olyan A: Rn
Rm és u ∈ int Dom(f). Azt mondjuk, hogy f differenciálható az u pontban, ha létezik olyan A: Rn  Rm lineáris leképezés, hogy
Rm lineáris leképezés, hogy
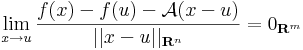
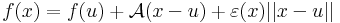
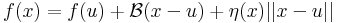
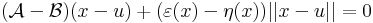
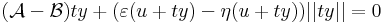
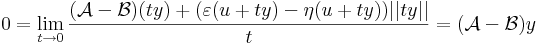
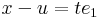
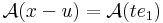
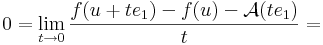
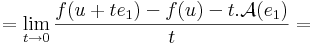
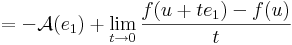
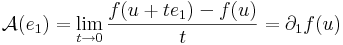
![[\mathrm{d}f(u)]=\mathbf{J}^f(u)=\begin{bmatrix}
\partial_1 f_1(u) & \partial_2 f_1(u) & \dots & \partial_n f_1(u)\\
\partial_1 f_2(u) & \partial_2 f_2(u) & \dots & \partial_n f_2(u)\\
\vdots & \vdots & \ddots & \vdots \\
\partial_1 f_m(u) & \partial_2 f_m(u) & \dots & \partial_n f_m(u)\\
\end{bmatrix}](/upload/math/b/c/8/bc8c1cf3c3d6f5032a7858552cc82a3a.png)
 parciális differenciálhatóság
parciális differenciálhatóság
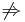 teljes differenciálhatóság
teljes differenciálhatóság