Matematika A2a 2008/6. gyakorlat
- Ez az szócikk a Matematika A2a 2008 alszócikke.
Folytonosság és totális differenciálhatóság
Tekintsük az
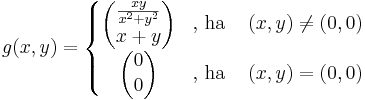
Ekkor
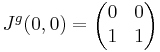
Viszont g nem totálisan diffható, mert a (t,t) mentén a (0,0)-ba tartva:
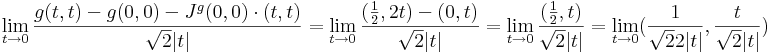
ami nem létezik.
Megjegyzés. Itt persze g nem folytonos, és itt is igaz az, hogy ha totálisan differenciálható egy függvény, akkor folytonos is:
Tétel. Ha f differenciálható u-ban, akkor ott folytonos is, ugyanis minden x-re:
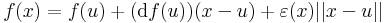
amely tagjai mind folytonosak u-ban.
Iránymenti deriválhatóság és differenciálhatóság
Példa.
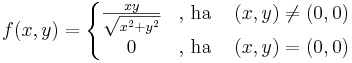
Ekkor
![\mathrm{J}^f(0,0)=[0, 0]\,](/upload/math/5/8/4/5844bda58422be338e9d02beef5b1e3e.png)
Ha tehát differenciálható, akkor az iránymenti deriváltak (Gateau-deriváltak) is léteznek (e egységvektor):
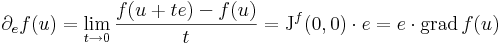
Ám, polárkoordinátákra áttérve:
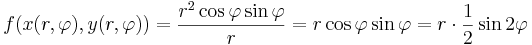
φ = π/4-et és π + π/4-et véve a vetületfüggvény a
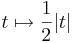 ,
,
ami nem differenciálható a 0-ban.
Megjegyzés. Persze abból, hogy az összes iránymenti derivált létezik, abból nem következik, hogy a függvény totálisan deriválható:
Egyváltozós illetve valós értékű függvény deriváltja
Ha f:Rn  R, akkor a definíciót még így is ki szokás mondani:
R, akkor a definíciót még így is ki szokás mondani:
f diffható r0-ban, ha létezik m vektor, hogy
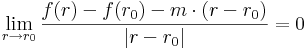
Ekkor az m a gradiensvektor, melynek sztenderd bázisbeli koordinátamátrixa a Jacobi mátrix:
![\mathrm{grad}\,f(r_0)=[\partial_1f(r_0),...,\partial_nf(r_0)]](/upload/math/3/e/b/3eba003f785c5389da9668d5a2fb9279.png)
Ha f:R Rn, akkor a definíciót még így is ki szokás mondani:
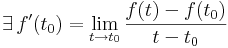
és ekkor f'(t0) a t0-beli deriváltvektor (ha t az idő és r=f(t) a hely, akkor ez a sebeségvektor).
Ha f:Rn Rn, akkor a differenciált deriválttenzornak is nevezik.
Példa.
Mi az
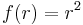 ,
,
skalárfüggvény gradiense?
Válasszuk le a lineáris részét!
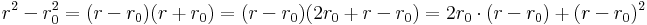
Itt az első tag a lineáris, a második a magasabbfokú. Tehát:
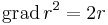
Lineáris és affin függvény deriváltja
Tétel. Az A : Rn  Rm lineáris leképezés differenciálható és differenciálja minden pontban saját maga:
Rm lineáris leképezés differenciálható és differenciálja minden pontban saját maga:
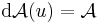
Ugyanis, legyen u ∈ Rn. Ekkor
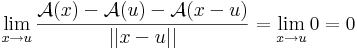
Tétel. Az azonosan c konstans függény esetén az dc(u)  0 alkalmas differenciálnak, mert
0 alkalmas differenciálnak, mert
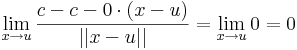
Tétel. Ha f és g a H ⊆ Rn halmazon értelmezett Rm-be képező, az u ∈ H-ban differenciálható függvények, akkor minden λ számra
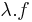 is differenciálható u-ban és
is differenciálható u-ban és 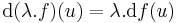 és
és
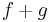 is differenciálható u-ban és
is differenciálható u-ban és 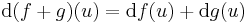
Ugyanis, a mondott differenciálokkal és a
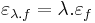
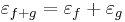
választással, ezek az u-ban folytonosak lesznek és a lineáris résszekel együtt ezek előállítják a skalárszoros és összegfüggvények megváltozásait.
Következmény. Tehát minden u ∈ Rn-re az affin c+A diffható és
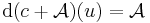
Példa
Az A: x  2x1 + 3x2 - 4x3 lineáris leképezés differenciálja az u pontban az u-tól független
2x1 + 3x2 - 4x3 lineáris leképezés differenciálja az u pontban az u-tól független
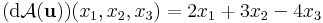
és Jacobi-mátrixa a konstans
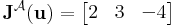
mátrix.
Világos, hogy a
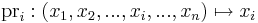
koordináta vagy projekciófüggvény lineáris, differenciálja minden u pontban saját maga és ennek mátrixa:
![[\mathrm{grad}\,\mathrm{pr_i}]=\mathbf{J}^{\mathrm{pr}_i}(\mathbf{u})=\begin{bmatrix}0 & 0 & ... & 1 & ...& 0\end{bmatrix}](/upload/math/f/a/5/fa51c1bb60d1e414a5acb5c8e93ae7d2.png)
ahol az 1 az i-edik helyen áll. Másként
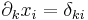
ahol
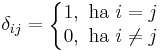
azaz a Kronecker-féle δ szimbólum.
Kiegészítés
Skalárfüggvények szorzata
λ, μ: H R, ahol H ⊆ Rn és az u ∈ H-ban mindketten differenciálhatók, akkor λμ is és
![[\mathrm{d}(\lambda\mu)(u)]_{1j}=\partial_j(\lambda\mu)=\mu\partial_j\lambda+\lambda\partial_j\mu=[\mu(u).\mathrm{grad}\,\lambda(u)+\lambda(u).\mathrm{grad}\,\mu(u)]_{j}](/upload/math/c/0/6/c06d0e7630e5abf100915f67de31ed5d.png)
azaz
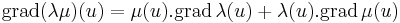
Példa
Számoljuk ki r2 deriváltját a szorzat szabálya szerint.
Egyrészt, ha r ≠ 0, akkor
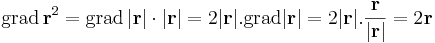
Másrészt, ha r = 0, akkor
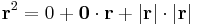
minden r-re fennáll, így grad(id2)(0) = 0 alkalmas az ε(r)=|r|-rel, tehát r2 differenciálható 0-ban is.
a × ... operátor
Differenciálható-e és ha igen mi a differenciálja, divergenciája, rotációja a
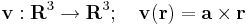
leképezésnek, ahol a előre megadott konstans vektor.
Megoldás
Az a × ..., azaz az
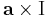
(itt I az identitás leképezés) leképezés lineáris, minthogy a vektoriális szorzás mindkét változójában lineáris (v ∈ Lin(R3;R3)), így differenciálható és differenciálja saját maga:
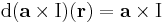
azaz
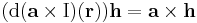
minden h és r ∈ R3 vektorra.
Jacobi-mátrixa (a sztenderd bázisbeli mátrixa) tetszőleges (x,y,z) pontban:
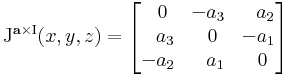
Mivel a főátlóbeli elemek mind nullák, ezért ebből rögtön következik, hogy div(a × I)(r) = 0.
![[\mathrm{rot}\,\mathbf{v}]_i=\varepsilon_{ijk}\partial_j\varepsilon_{klm}a_lx_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\partial_j x_m=\varepsilon_{ijk}\varepsilon_{klm}a_l\delta_{jm}=\varepsilon_{ijk}\varepsilon_{klj}a_l=](/upload/math/6/4/2/642b95a997703a68637ff5897331d591.png)
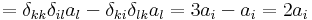
azaz rot v (r) = 2a. Az előbb felhasználtuk a kettős vektoriális szorzatra vonatkozó kifejtési tétel indexes alakját, a
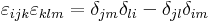
ami azt mondja, hogy ha az ijk és klm-ben a nem azonos párok jó sorrendben következnek, akkor az epszolon 1-et, ha rossz sorrendben, akkor -1-et ad.
a  ... operátor
... operátor
Differenciálható-e és ha igen mi a differenciálja
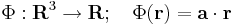
leképezésnek, ahol a előre megadott konstans vektor.
Megoldás
Skalártér lévén Φ gradiensét kell kiszámolnunk. Mivel ez is lineáris leképezés, ezért differenciálható és differenciálja saját maga, azaz a gradiens vektor pont a:
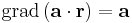
Ezt persze indexes deriválással is kiszámítható:
![[\mathrm{grad}\,\Phi]_i=\partial_ia_kx_k=a_k\partial_ix_k=a_k\delta_{ik}=a_i\,](/upload/math/e/6/7/e67c528d00633fe5efe34a67e9c2aef9.png)
További példa skalárfüggvényre
Hatérozzuk meg a Φ
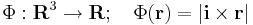
(ahol i az x irányú egységvektor, |.| a vektor hossza) függvény szintvonalait, differenciálhatóságát, gradiensét!
Megoldás
Érdemes koordinátás írásmódra áttérni, hiszen az i vektor úgy is a koordinátarendszerhez kapcsolódik. A vektoriális szorzás definíciója miatt
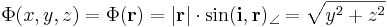
Tehát azok a pontok vannak azonos szintfelületen, melyeknek az [yz] síkra vett vetületük azonos hosszúságú (i × r hossza az i-re merőleges komponense r-nek). Az
- y2 + z2 = 0
egyenlettel megadott pontokban (másként: y = 0 & z = 0 & x tetszőleges) a függvény nem differenciálható, ugyanis a Φ=0 szintfelület elfajúlt módon csak egy egyenes, az x tengely, így a gradiens vektor iránya nem egyértelmű. Ezt azzal is igazolhatjuk, ha vesszük ezekben a pontokban például az y irányú parciális függvényt:
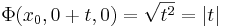
azaz az (x0,0,0) pontokhoz tartozó Φ(x0, . ,0) parciális függvény nem differenciálható a 0-ban.
Máshol a gradiensvektor, a parciális deriváltakat kiszámítva
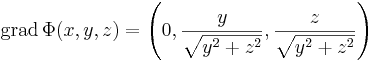
vagy másként:
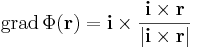
Megjegyezzük, hogy ehhez még a függvénykompozíció deriválási szabályával is lejuthattunk volna:
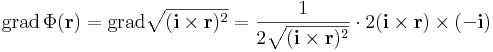
Indexes deriválás
Most csak a sokféle szorzat deriváltjának értékét számítjuk ki. Minden esetben igazolható, hogy ha a formulákban szereplő összes derivált létezik, akkor a formula érvényes (sőt, ha a függvények az adott pontban differenciálhatók, akkor a szorzat is differenciálható az adott pontban). Az mátrixelemeket indexesen számítjuk.
Feltéve például, hogy az f többváltozós skalárfüggvény parciálisan differenciálható, a gradiens elemeit így nyerjük:
![[\mathrm{grad}\,f]_i=\partial_if\,](/upload/math/f/a/3/fa3c940fa1fad80ffb905f790caa7495.png)
1. Példa
Ha f(r) = r2, akkor
![\mathbf{r}^2=\sum\limits_{k=1}^3 [\mathbf{r}]_k[\mathbf{r}]_k=\sum\limits_{k=1}^3 x_kx_k=[\mathrm{Einstein\;konv.}]\;x_kx_k](/upload/math/d/8/b/d8b7a2ddcfd984008eedaf9f2fc25505.png)
![[\mathrm{grad}\,f]_i=\partial_ix_kx_k\,=x_k\partial_ix_k+x_k\partial_ix_k\,](/upload/math/9/c/7/9c7478f0fc6c90cb7d94d0f617d8d49a.png)
de a koordinátafüggvények deriváltjairól tudjuk, hogy azoknak az értékét a Kronecker-delta adja:
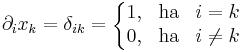
azaz
![[\mathrm{grad}\,f]_i=2x_k\delta_{ik}=2x_i=[2\mathbf{r}]_i\,](/upload/math/d/7/8/d784a387f1c950a3e0e038cc56a61cbd.png)
tehát parciálisan differenciálható minden pontban és a Jacobi-mártix elemei a fentiek.
2. Példa
Ha f(r) = ar, akkor
![[\mathrm{grad}\,f]_i=\partial_ia_kx_k\,=a_k\partial_ix_k=a_k\delta_{ik}\,=a_i=[\mathbf{a}]_i](/upload/math/a/5/7/a57f9bc5e37f361c19f92eee518f6f06.png)
3. Példa
Ha f(r) = |r|α, akkor
![[\mathrm{grad}\,f]_i=\partial_i(x_kx_k)^{\alpha/2}\,=\partial_i(x_k)^{\alpha}=\frac{\alpha}{2}(x_kx_k)^{\frac{\alpha}{2}-1}2\delta_{ik}x_k\,](/upload/math/7/1/8/71892bcadec17b766681f84d469b9ff3.png)
itt ne feledjük, hogy k-ra szummázunk és hogy az összetett tényezőben a skaláris szorzat szerepel:
![[\mathrm{grad}\,f]_i=\alpha(x_kx_k)^{\frac{\alpha}{2}-1}x_i\,=\left[\alpha|\mathbf{r}|^\alpha\frac{\mathbf{r}}{\mathbf{r}^2}\right]_i=\left[\alpha|\mathbf{r}|^{\alpha-1}\frac{\mathbf{r}}{|\mathbf{r}|}\right]_i](/upload/math/0/d/e/0ded0710fdc3c526de84bc11a3747b26.png)
tehát parciálisan differenciálható minden pontban és a Jacobi-mártix elemei a fentiek.
Deriválttenzor és invariánsai
Ha A az f:Rn ⊃ Rn leképezés differenciálja az u pontban, akkor A-t deriválttenzornak nevezzük. Minden tenzor egyértelműen előáll egy szimmetrikus és egy antiszimmetrikus tenzor összegeként:
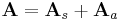
Ebből a szimmetrikus rész főátlbeli elemeinek összege minden bázisban ugyanaz a skaláris érték, melyet a tenzor nyomának, illetve a függvény divergenciájának nevezzük:
 illetve
illetve 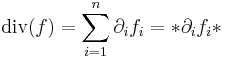
Az utóbbi írásmód a koordinátás alakban az úgy nevezett Einstein-féle jelölési konvenció, amelynek elve, hogy a kétszer stereplő indexekre automatikusan szumma értendő.
Példa
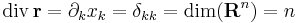
f:R3 ⊃ R3
esetben a tenzor antiszimmetrikus részéhez egyértelműen létezik egy olyan a vektor, hogy minden r-re:
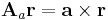
mely vektort az f rotációjának nevezzük:
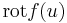 és
és ![[\mathrm{rot}f(u)]_i=\sum\limits_{j,k=1}^3\varepsilon_{ijk}\partial_j f_k=*\varepsilon_{ijk}\partial_j f_k*](/upload/math/b/e/d/bed2ac05c3c84c0a2da64ec31206b3fa.png)
ahol
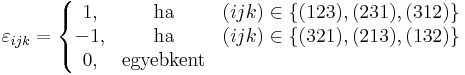
a Levi-Civita-szimbólum.
Skalárfüggvénnyel való szorzás
λ: H R, f:H Rm, ahol H ⊆ Rn és az u ∈ H-ban mindketten differenciálhatók, akkor λ.f is és
![[\mathrm{d}(\lambda.f)(u)]_{ij}=\partial_j(\lambda.f)=\partial_j\lambda f_i=f_i\partial_j\lambda+\lambda \partial_jf_i](/upload/math/3/f/f/3ff67b8cf3567d0fa54ce6ef1b76ee50.png)
azaz
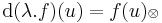
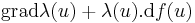
ahol 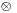 a diadikus szorzat, melynek koordinátamátrixa egy oszlopvektor (balról) és egy sorvektor (jobbról) mátrixszorzatából adódik. Ez ritkán kell teljes egészében, a két invariáns (rot-nál csak 3×3-as esetben) a gyakoribb.
a diadikus szorzat, melynek koordinátamátrixa egy oszlopvektor (balról) és egy sorvektor (jobbról) mátrixszorzatából adódik. Ez ritkán kell teljes egészében, a két invariáns (rot-nál csak 3×3-as esetben) a gyakoribb.
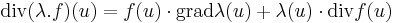
![[\mathrm{rot}(\lambda.f)(u)]_i=\varepsilon_{ijk}\partial_j\lambda f_k=\varepsilon_{ijk}(\partial_j\lambda)f_k+\lambda\varepsilon_{ijk}\partial_jf_k=](/upload/math/1/5/f/15f80c722939d5d24dd53873f04b0f4c.png)
![=[\mathrm{grad}\lambda(u)\times f(u)+\lambda(u).\mathrm{rot}f(u)]_i](/upload/math/3/3/c/33c3ed5ec40fd5cce155b403e1e0596f.png)
Vektorfüggvények skaláris szorzata
f,g:H Rm, ahol H ⊆ Rn és az u ∈ H-ban mindketten differenciálhatók, akkor fg is és
![[\mathrm{d}(f\cdot g)(u)]_{1j}=\partial_j(f\cdot g)=\partial_j f_kg_k=f_k\partial_j g_k+g_k \partial_j f_k](/upload/math/a/b/e/abe7bd7e0906b512cebfb33fda537ad4.png)
azaz
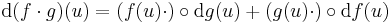
illetve a Jacobi-mátrixszal:
![\mathbf{J}^{f\cdot g}(u)=[f(u)]^\mathrm{T}\cdot \mathbf{J}^g(u) +
[g(u)]^\mathrm{T}\cdot \mathbf{J}^f(u)](/upload/math/0/4/8/048559240cdb9844693361f4d89d42b3.png)
ahol [.]T az oszlopvektor transzponáltját, 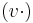 pedig a v vektorral történő skaláris szorzás operátorát jelöli.
pedig a v vektorral történő skaláris szorzás operátorát jelöli.
| 5. gyakorlat | 7. gyakorlat |